 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIGER: Traceable Inference with Graph-Based Evidence Routing for Mitigating Hallucinations in Multimodal Generation
May 29, 2026We study fact-level repair for multimodal generation, where a fluent output may contain specific facts that are not supported by the input. Existing inference-time repair methods often generate feedback by jointly conditioning on the input and the current output. This design has two limitations: hallucinated claims in the output can bias the model's interpretation of the input, and free-form feedback cannot be ranked or scheduled at the fact level. We present TIGER, an inference-time framework that redesigns feedback for localized repair. TIGER independently extracts an observation graph from the input and a claim graph from the current output, then assigns each claim a graph-conditioned risk score based on support and conflict. The model repairs selected high-risk claims while keeping the backbone frozen. We provide a convergence analysis showing that the expected total risk decreases geometrically to an explicit asymptotic bound under mild assumptions. Experiments across four cross-modal paths, including image-to-text, image+text-to-text, audio-to-text, and video-to-text, show that TIGER reduces unsupported content while preserving task quality. The gains hold across multiple backbones, and a CrisisFACTS case study suggests that the same repair mechanism can improve grounding in multi-source settings.
GraphIP-Bench: How Hard Is It to Steal a Graph Neural Network, and Can We Stop It?
May 12, 2026Graph neural networks (GNNs) deployed as cloud services can be \emph{stolen} through \emph{model-extraction attacks}, which train a surrogate from query responses to reproduce the target's behaviour, and a growing line of ownership defenses tries to prevent or trace such theft. The title of this paper asks two questions: \emph{how hard is it to steal a GNN?}, and \emph{can we stop it?} Prior work cannot answer either, because experiments use inconsistent datasets, threat models, and metrics. We introduce \emph{GraphIP-Bench}, a unified benchmark which evaluates both sides under a single black-box protocol. It integrates twelve extraction attacks, twelve defenses spanning watermarking, output-perturbation, and query-pattern-detection families, ten public graphs covering homophilic, heterophilic, and large-scale regimes, three GNN backbones, and three graph-learning tasks, and it reports fidelity, task utility, ownership verification, and computational cost on shared splits, queries, and budgets. We further add a joint attack-and-defense track which runs every attack on every defended target and measures watermark verification on the resulting surrogate, which exposes the protection that a defense retains after extraction. The empirical picture is short: stealing a GNN is easy at medium query budgets and most defenses do not change this; several watermarks verify reliably on the protected model but lose most of their verification signal on the extracted surrogate, which exposes a gap that single-model evaluations miss; and heterophilic graphs are systematically harder to steal, while a cross-architecture mismatch between target and surrogate reduces but does not prevent extraction. Code: \href{https://github.com/LabRAI/GraphIP-Bench}{LabRAI/GraphIP-Bench}.
EpiGraph: A Knowledge Graph and Benchmark for Evidence-Intensive Reasoning in Epilepsy
May 10, 2026Epilepsy diagnosis and treatment require evidence-intensive reasoning across heterogeneous clinical knowledge, including biosignal patterns, genetic mechanisms, pharmacogenomics, treatment strategies, and patient outcomes. In this work, we present \textsc{EpiGraph}, a large-scale epilepsy knowledge graph and benchmark for evaluating knowledge-augmented clinical reasoning. \textsc{EpiGraph} integrates 48,166 peer-reviewed papers and seven clinical resources into a heterogeneous graph containing 24,324 entities and 32,009 evidence-grounded triplets across five clinical layers. Built upon this graph, \textsc{EpiBench} defines five clinically motivated tasks spanning clinical decision-making, EEG report generation, pharmacogenomic precision medicine, treatment recommendation, and deep research planning. We evaluate six LLMs under both standard and Graph-RAG settings. Results show that integrating \textsc{EpiGraph} consistently improves performance across all tasks, with the largest gains observed in pharmacogenomic reasoning (+30--41\%). Our findings demonstrate that structured epilepsy knowledge substantially enhances evidence-grounded clinical reasoning and provides a practical benchmark framework for evaluating knowledge-augmented LLMs in real-world neurological settings. Our code is available at: https://github.com/LabRAI/EEG-KG.
An Analysis of Active Learning Algorithms using Real-World Crowd-sourced Text Annotations
Apr 25, 2026Active learning algorithms automatically identify the most informative samples from large amounts of unlabeled data and tremendously reduce human annotation effort in inducing a machine learning model. In a conventional active learning setup, the labeling oracles are assumed to be infallible, that is, they always provide correct answers (in terms of class labels) to the queried unlabeled instances, which cannot be guaranteed in real-world applications. To this end, a body of research has focused on the development of active learning algorithms in the presence of imperfect / noisy oracles. Existing research on active learning with noisy oracles typically simulate the oracles using machine learning models; however, real-world situations are much more challenging, and using ML models to simulate the annotation patterns may not appropriately capture the nuances of real-world annotation challenges. In this research, we first collect annotations of text samples (from 3 benchmark text classification datasets) from crowd-sourced workers through a crowd-sourcing platform. We then conduct extensive empirical studies of 8 commonly used active learning techniques (in conjunction with deep neural networks) using the obtained annotations. Our analyses sheds light on the performance of these techniques under real-world challenges, where annotators can provide incorrect labels, and can also refuse to provide labels. We hope this research will provide valuable insights that will be useful for the deployment of deep active learning systems in real-world applications. The obtained annotations can be accessed at https://github.com/varuntotakura/al_rcta/.
* The proposed dataset can be accessed at https://github.com/varuntotakura/al_rcta/. To appear in Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN 2026)
Optimizing EEG Graph Structure for Seizure Detection: An Information Bottleneck and Self-Supervised Learning Approach
Apr 02, 2026Seizure detection from EEG signals is highly challenging due to complex spatiotemporal dynamics and extreme inter-patient variability. To model them, recent methods construct dynamic graphs via statistical correlations, predefined similarity measures, or implicit learning, yet rarely account for EEG's noisy nature. Consequently, these graphs usually contain redundant or task-irrelevant connections, undermining model performance even with state-of-the-art architectures. In this paper, we present a new perspective for EEG seizure detection: jointly learning denoised dynamic graph structures and informative spatial-temporal representations guided by the Information Bottleneck (IB). Unlike prior approaches, our graph constructor explicitly accounts for the noisy characteristics of EEG data, producing compact and reliable connectivity patterns that better support downstream seizure detection. To further enhance representation learning, we employ a self-supervised Graph Masked AutoEncoder that reconstructs masked EEG signals based on dynamic graph context, promoting structure-aware and compact representations aligned with the IB principle. Bringing things together, we introduce Information Bottleneck-guided EEG SeizuRE DetectioN via SElf-Supervised Learning (IRENE), which explicitly learns dynamic graph structures and interpretable spatial-temporal EEG representations. IRENE addresses three core challenges: (i) Identifying the most informative nodes and edges; (ii) Explaining seizure propagation in the brain network; and (iii) Enhancing robustness against label scarcity and inter-patient variability. Extensive experiments on benchmark EEG datasets demonstrate that our method outperforms state-of-the-art baselines in seizure detection and provides clinically meaningful insights into seizure dynamics. The source code is available at https://github.com/LabRAI/IRENE.
CITED: A Decision Boundary-Aware Signature for GNNs Towards Model Extraction Defense
Feb 23, 2026Graph neural networks (GNNs) have demonstrated superior performance in various applications, such as recommendation systems and financial risk management. However, deploying large-scale GNN models locally is particularly challenging for users, as it requires significant computational resources and extensive property data. Consequently, Machine Learning as a Service (MLaaS) has become increasingly popular, offering a convenient way to deploy and access various models, including GNNs. However, an emerging threat known as Model Extraction Attacks (MEAs) presents significant risks, as adversaries can readily obtain surrogate GNN models exhibiting similar functionality. Specifically, attackers repeatedly query the target model using subgraph inputs to collect corresponding responses. These input-output pairs are subsequently utilized to train their own surrogate models at minimal cost. Many techniques have been proposed to defend against MEAs, but most are limited to specific output levels (e.g., embedding or label) and suffer from inherent technical drawbacks. To address these limitations, we propose a novel ownership verification framework CITED which is a first-of-its-kind method to achieve ownership verification on both embedding and label levels. Moreover, CITED is a novel signature-based method that neither harms downstream performance nor introduces auxiliary models that reduce efficiency, while still outperforming all watermarking and fingerprinting approaches. Extensive experiments demonstrate the effectiveness and robustness of our CITED framework. Code is available at: https://github.com/LabRAI/CITED.
CREDIT: Certified Ownership Verification of Deep Neural Networks Against Model Extraction Attacks
Feb 23, 2026Machine Learning as a Service (MLaaS) has emerged as a widely adopted paradigm for providing access to deep neural network (DNN) models, enabling users to conveniently leverage these models through standardized APIs. However, such services are highly vulnerable to Model Extraction Attacks (MEAs), where an adversary repeatedly queries a target model to collect input-output pairs and uses them to train a surrogate model that closely replicates its functionality. While numerous defense strategies have been proposed, verifying the ownership of a suspicious model with strict theoretical guarantees remains a challenging task. To address this gap, we introduce CREDIT, a certified ownership verification against MEAs. Specifically, we employ mutual information to quantify the similarity between DNN models, propose a practical verification threshold, and provide rigorous theoretical guarantees for ownership verification based on this threshold. We extensively evaluate our approach on several mainstream datasets across different domains and tasks, achieving state-of-the-art performance. Our implementation is publicly available at: https://github.com/LabRAI/CREDIT.
TIFO: Time-Invariant Frequency Operator for Stationarity-Aware Representation Learning in Time Series
Feb 19, 2026Nonstationary time series forecasting suffers from the distribution shift issue due to the different distributions that produce the training and test data. Existing methods attempt to alleviate the dependence by, e.g., removing low-order moments from each individual sample. These solutions fail to capture the underlying time-evolving structure across samples and do not model the complex time structure. In this paper, we aim to address the distribution shift in the frequency space by considering all possible time structures. To this end, we propose a Time-Invariant Frequency Operator (TIFO), which learns stationarity-aware weights over the frequency spectrum across the entire dataset. The weight representation highlights stationary frequency components while suppressing non-stationary ones, thereby mitigating the distribution shift issue in time series. To justify our method, we show that the Fourier transform of time series data implicitly induces eigen-decomposition in the frequency space. TIFO is a plug-and-play approach that can be seamlessly integrated into various forecasting models. Experiments demonstrate our method achieves 18 top-1 and 6 top-2 results out of 28 forecasting settings. Notably, it yields 33.3% and 55.3% improvements in average MSE on the ETTm2 dataset. In addition, TIFO reduces computational costs by 60% -70% compared to baseline methods, demonstrating strong scalability across diverse forecasting models.
RULERS: Locked Rubrics and Evidence-Anchored Scoring for Robust LLM Evaluation
Jan 13, 2026The LLM-as-a-Judge paradigm promises scalable rubric-based evaluation, yet aligning frozen black-box models with human standards remains a challenge due to inherent generation stochasticity. We reframe judge alignment as a criteria transfer problem and isolate three recurrent failure modes: rubric instability caused by prompt sensitivity, unverifiable reasoning that lacks auditable evidence, and scale misalignment with human grading boundaries. To address these issues, we introduce RULERS (Rubric Unification, Locking, and Evidence-anchored Robust Scoring), a compiler-executor framework that transforms natural language rubrics into executable specifications. RULERS operates by compiling criteria into versioned immutable bundles, enforcing structured decoding with deterministic evidence verification, and applying lightweight Wasserstein-based post-hoc calibration, all without updating model parameters. Extensive experiments on essay and summarization benchmarks demonstrate that RULERS significantly outperforms representative baselines in human agreement, maintains strong stability against adversarial rubric perturbations, and enables smaller models to rival larger proprietary judges. Overall, our results suggest that reliable LLM judging requires executable rubrics, verifiable evidence, and calibrated scales rather than prompt phrasing alone. Code is available at https://github.com/LabRAI/Rulers.git.
MolEdit: Knowledge Editing for Multimodal Molecule Language Models
Nov 16, 2025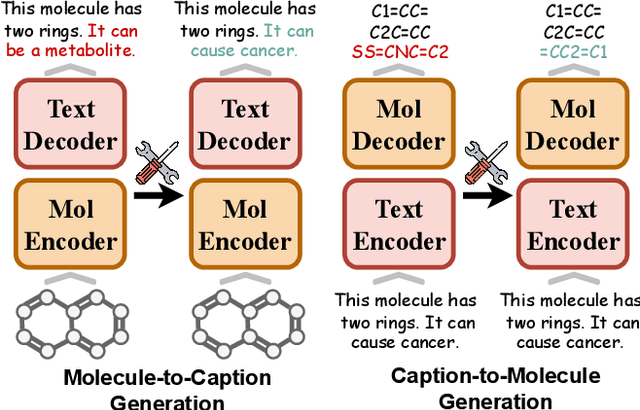



Understanding and continuously refining multimodal molecular knowledge is crucial for advancing biomedicine, chemistry, and materials science. Molecule language models (MoLMs) have become powerful tools in these domains, integrating structural representations (e.g., SMILES strings, molecular graphs) with rich contextual descriptions (e.g., physicochemical properties). However, MoLMs can encode and propagate inaccuracies due to outdated web-mined training corpora or malicious manipulation, jeopardizing downstream discovery pipelines. While knowledge editing has been explored for general-domain AI, its application to MoLMs remains uncharted, presenting unique challenges due to the multifaceted and interdependent nature of molecular knowledge. In this paper, we take the first step toward MoLM editing for two critical tasks: molecule-to-caption generation and caption-to-molecule generation. To address molecule-specific challenges, we propose MolEdit, a powerful framework that enables targeted modifications while preserving unrelated molecular knowledge. MolEdit combines a Multi-Expert Knowledge Adapter that routes edits to specialized experts for different molecular facets with an Expertise-Aware Editing Switcher that activates the adapters only when input closely matches the stored edits across all expertise, minimizing interference with unrelated knowledge. To systematically evaluate editing performance, we introduce MEBench, a comprehensive benchmark assessing multiple dimensions, including Reliability (accuracy of the editing), Locality (preservation of irrelevant knowledge), and Generality (robustness to reformed queries). Across extensive experiments on two popular MoLM backbones, MolEdit delivers up to 18.8% higher Reliability and 12.0% better Locality than baselines while maintaining efficiency. The code is available at: https://github.com/LzyFischer/MolEdit.